|
◎文╱高雄記者毛志民
115年度藥師週刊全國記者教育訓練營,國立東華大學教育與潛能開發學系教授李明憲以「週刊記者與時代科技AI的邂逅」為題授課,課中以ChatGPT與Gemini為例,示範避免個資被用於訓練AI模型設定,值得藥師參考。
李明憲提醒無論使用哪款AI工具,都應避免輸入以下資訊:身分證字號、銀行帳號、醫療報告、學術機密及帳號密碼等;若需討論涉及個人的案例,建議事先去識別化,將敏感資訊匿名化後再輸入。
隨著日常使用AI於服務、教學與研究,許多人擔心對話內容被用來訓練模型,分別以ChatGPT與Gemini為例,說明隱私保護設定步驟:
一、ChatGPT(OpenAI)
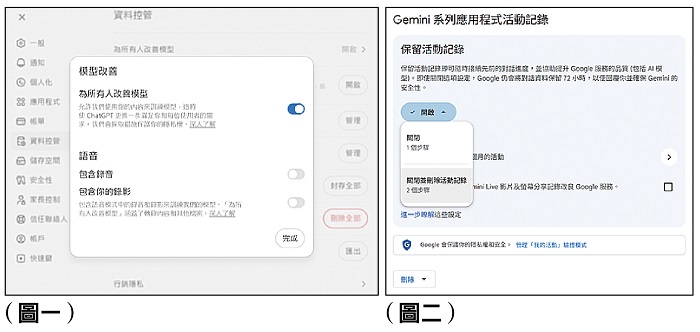
首先,關閉「用於改進模型」的授權設定是最直接的做法。在網頁版中,點擊右上角頭像,進入「設定」,切換至「資料控管」頁籤,找到「為所有人改善模型」選項並將其關閉。手機APP操作路徑相同,同樣在「設定→資料控管」中關閉該選項(圖一)。完成後,後續對話便不會被用於訓練模型。
其次,若需討論敏感內容,建議使用「臨時聊天(Temporary
Chat)」模式。此模式下的對話不會存入歷史紀錄,也不會用於訓練,但系統仍可能基於安全需求短暫保留約30天。
二、Gemini(Google)
在Gemini的設定中,進入「Gemini應用程式活動」頁面,關閉「活動儲存」開關,即可阻止日後對話被保留或用於改善模型。此外,可設定自動刪除期限(如三個月),或手動清除既有歷史紀錄。對於敏感查詢,同樣建議改用「臨時對話」模式,通常不會被納入訓練資料。(圖二)
李明憲提醒即使關閉設定,Google仍會將對話資料保留72小時,於結束對話內容、備份後刪除,也是他慣用的方式。
對藥師而言,注視隱私極其重要,主動關閉訓練授權、善用臨時對話模式,並養成不輸入敏感資料的習慣;如此,方可消弭個人資料被用於AI訓練的風險。
回首頁 |
